


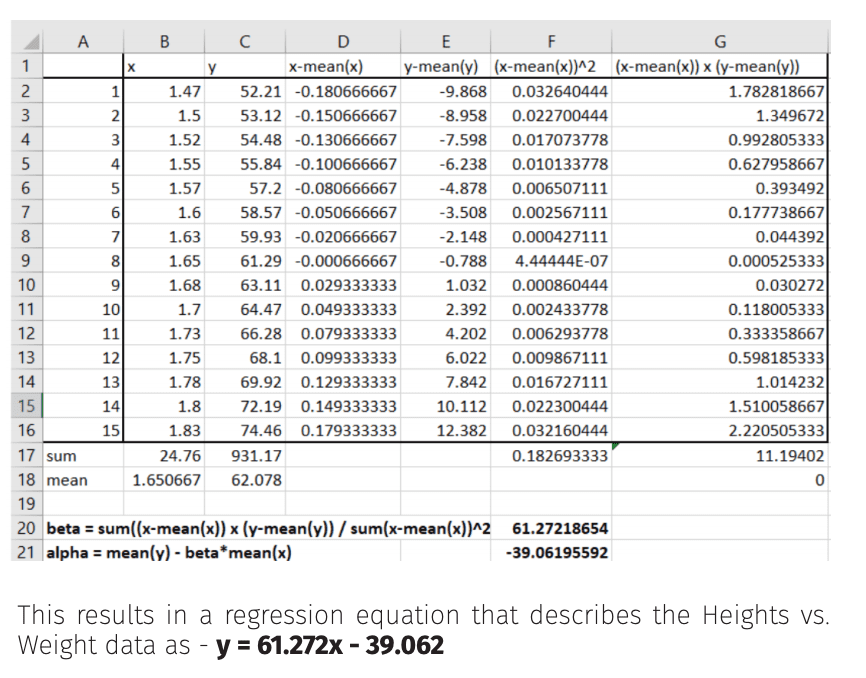
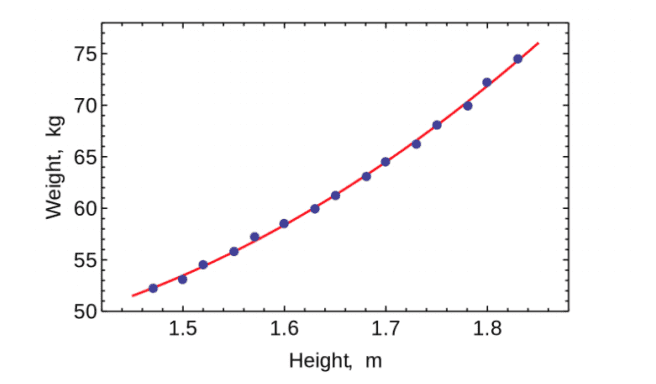
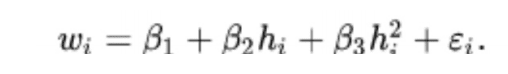
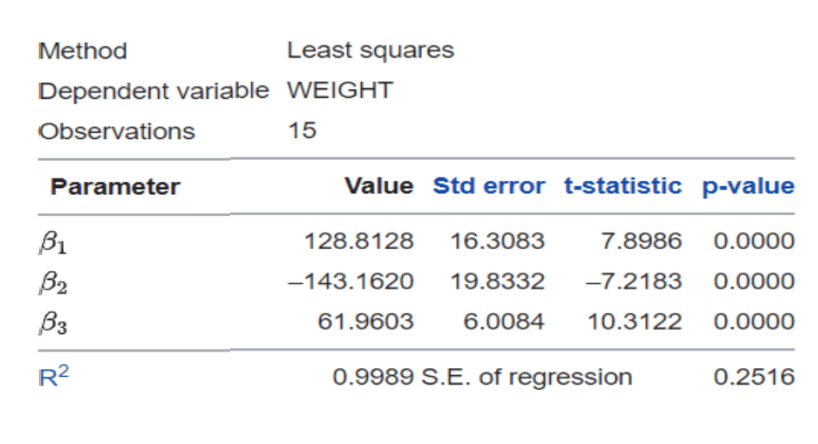

Paul Maxwell-Walters
A British software tester based in Sydney, Australia with about 10 years of experience testing in agriculture, financial services, digital media and energy consultancy. Paul is a co-chair and social media officer at the Sydney Testers Meetup Group, along with having spoken at several conferences in Australia. Paul blogs on issues in IT and testing at http://testingrants.blogspot.com.au and tweets on testing and IT matters at @TestingRants.